프로젝트 소개

요약
Point cloud 데이터는 주로 3D space에서 어떤 object 표면 위에 존재하는 점들의 집합을 의미합니다. 드론이나 자율주행자동차에 달려있는 Lidar 센서를 통해 수집되는 데이터가 이러한 point cloud 형태로 존재합니다. Point cloud는 일정한 간격의 grid 형태로 존재하는 2D 이미지 데이터와는 달리 공간 안의 점들이 여기저기 흩어져 있고, 점들의 density 역시 일정하지 않습니다. 또한 point들이 어떤 순서로 있던지 간에 형태는 항상 일정하게 유지된다는 점에서 점에서 permutation invariant 하다는 특성이 있습니다.
따라서 기존 2D 형태 학습에 최적화된 grid convolution 방식을 그대로 적용할 수는 없습니다. 2017년 CVPR에서 발표된 PointNet[2] 논문을 기점으로 point cloud 데이터에 deep learning을 적용한 연구 결과가 발표되고 있는데, 이번 프로젝트의 DGCNN 역시 PointNet의 구조를 응용한 것입니다. DGCNN의 특징을 요약하면 아래와 같습니다.
- EdgeConv라는 연산을 새롭게 추가하여 permutation invariance를 유지하며 포인트들의 local feature을 학습할 수 있도록 하였습니다.
- 레이어마다 포인트들의 관계 그래프를 dynamic하게 다시 구성하여 의미있는 grouping을 학습할 수 있도록 하였습니다. 이 논문에서 제시하고 있는 모델 아키텍처의 이름이 DGCNN(Dynamic Graph CNN)인 이유가 바로 여기에 있습니다.
DGCNN이 PointNet 기반으로 만들어졌기 때문에, PointNet 모델 구조를 먼저 살펴볼 필요가 있습니다.
PointNet
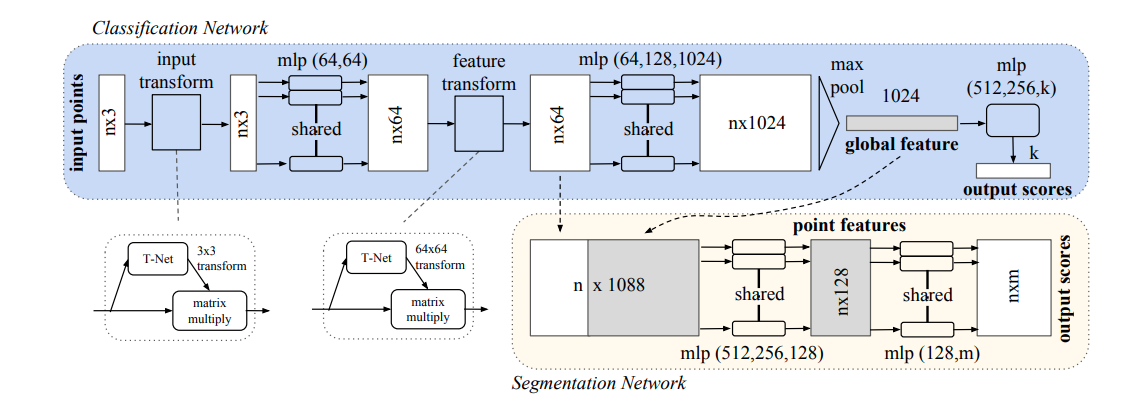 PointNet model architectures
PointNet model architectures
PointNet은 input points가 들어오면 permutation-invariant 연산인 mlp와 max pooling 을 사용하여 feature을 추출하는 것이 특징입니다. 여기서 feature transform에 해당하는 T-Net은 학습되는 point들의 feature들이 특정한 변환에 불변한 형태로 바꾸어주는 역할을 합니다. 예를 들어 point 전체를 회전한다고 하여 global point cloud의 카테고리나 point들의 segmentation 결과가 달라져서는 안되므로, T-Net의 affine transformation을 통해 이 문제를 해결했습니다. T-Net 역시 전체 모델 구조와 유사하게 mlp와 max pooling으로만 구성되어 있습니다. 이러한 T-Net의 아이디어는 Spatial Transformer Networks[3]의 개념과 비슷합니다. Segmentation 네트워크 구조에서는 global feature까지 고려하기 위해 위 그림에서와같이 이를 결합하여 입력으로 사용하는 것을 확인할 수 있습니다.
PointNet은 낱개 입력 point 하나하나의 좌표에 대한 연산을 하여 추출한 global feature를 사용하기 때문에 어떤 point 주변에 모여있는 local feature는 얻어낼 수 없다는 문제가 있습니다. 이후 저자들은 PointNet의 개선판인 PointNet++ 으로 local feature를 고려하는 방식을 제안하였지만 여기서는 다루지 않겠습니다.
DGCNN
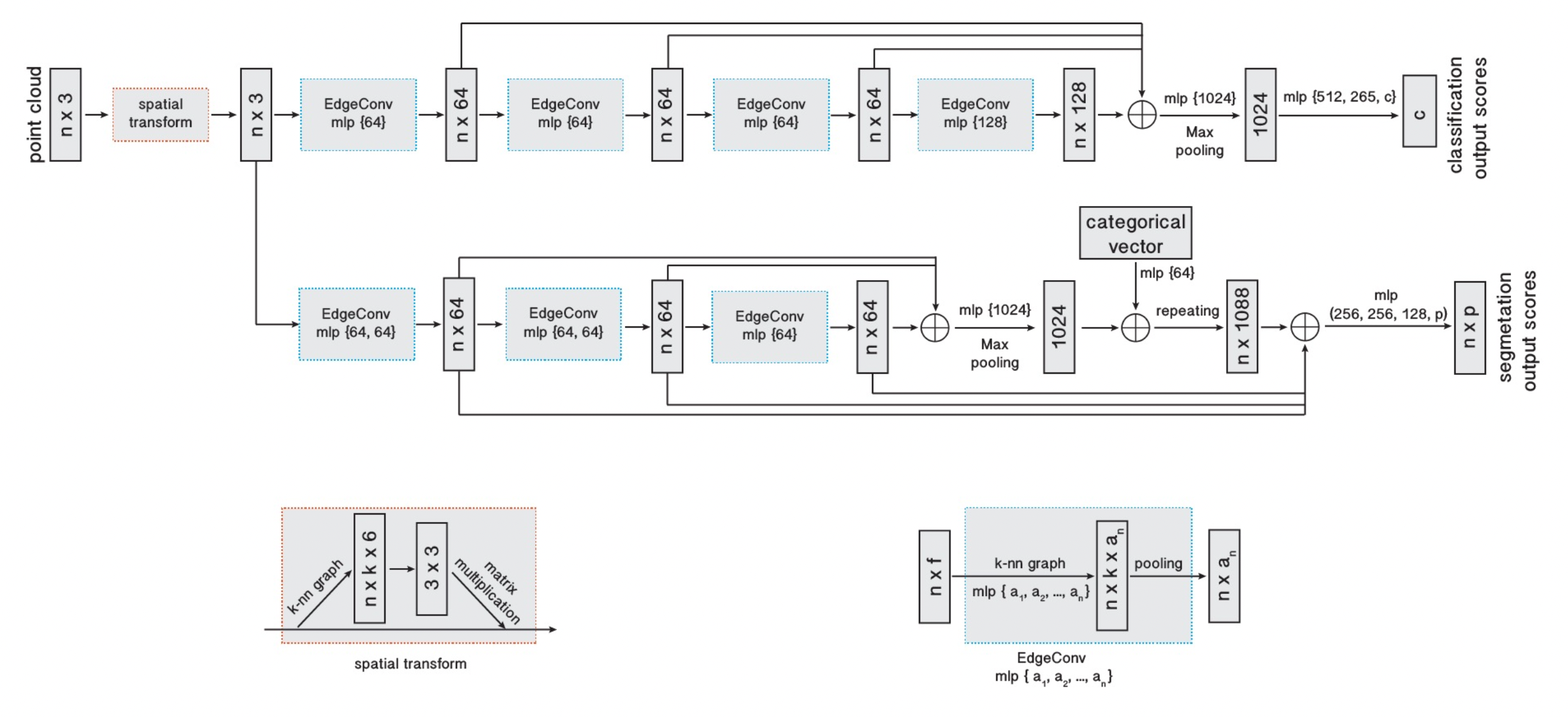 DGCNN model architectures
DGCNN model architectures
DGCNN의 모델 구조입니다. PointNet 모델 구조와 비슷하지만 EdgeConv가 새롭게 적용되었습니다. EdgeConv 연산이 적용될 때, k-NN을 사용하여 입력 그래프를 매번 새롭게 생성해줍니다. 따라서 첫 번째 EdgeConv에서는 input space에서 물리적으로 가까이 있는 k 개의 point들을 뽑아서 사용한다면, 그 다음 EdgeConv부터는 feature space에서 distance가 가까운 k 개의 point들을 새롭게 뽑아서 사용하게 됩니다.
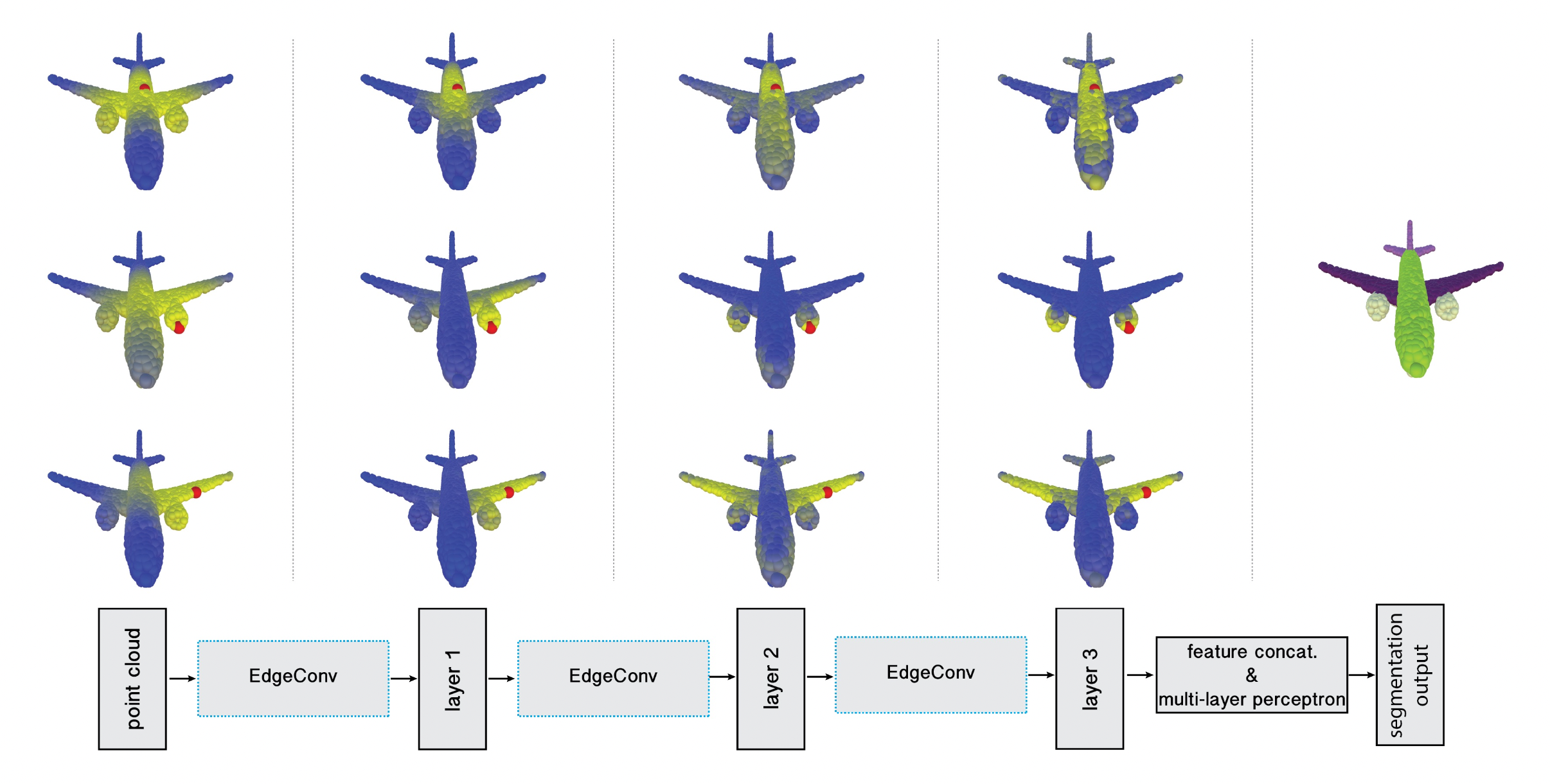 Point cloud segmentation using the proposed neural network
Point cloud segmentation using the proposed neural network
위 그림에서처럼 입력으로 들어온 point들 중에서 기준점(빨간색)을 찍어보면, input space 상에서 euclidean distance가 가까운 점들이 선택됩니다. 이 과정을 반복하여 뒷단으로 갈수록 feature space 상에서 가까운 점들을 추출하고 있는 것을 확인할 수 있습니다. 아래 코드에서 feature를 새롭게 추출해내는 부분은 get_graph_feature 함수로 구현되어 있습니다.
논문에서는 총 16,881개의 3D 데이터를 사용하였고, 각 데이터는 2048개의 points들로 샘플링 되었습니다. 총 16개의 object categories(비행기, 의자, 자동차 등)가 있고, 각 object별로 최대 6개 part(ex. 비행기: 날개, 몸통, 꼬리, 엔진)로 포인트들이 레이블링 되어져 있습니다. 아래 구현 부분에서는 빠른 실험을 위해 약 17,000개 중 2048개의 3D 데이터만을 사용하여 훈련하였습니다. Test셋 역시 일부만을 추출하여 사용하였고, 그 결과 81.17%의 mIoU를 보여주었습니다. 훨씬 적은 데이터셋을 사용하였기에 논문(85.2% mIoU)보다는 낮았습니다.
최근 인턴으로 일하고 있는 회사에서 3D 치아 데이터를 다루고 있어 이번 포스팅을 작성해보았습니다. 딥러닝을 적용하여 치아 데이터를 각각의 치아별로 segmentation해주는 프로젝트에 참여하게 되어 point cloud 및 DGCNN 모델 구조에 대해 자연스럽게 공부하게 되었습니다. 다음에는 이러한 point cloud에 적용될 수 있는 다른 모델 아키텍쳐들(ex. PointCNN, RandLA-Net 등)을 공부해 포스팅해보겠습니다.
Packages
필요한 패키지들을 불러옵니다.
1 | |
Arguments
하이퍼파라미터 값들이 저장된 딕셔너리를 생성합니다.
1 | |
1 | |
데이터 불러오기
필요한 데이터를 불러옵니다.
1 | |
1 | |
1 | |
| path | label | segmentation_part_num | |
|---|---|---|---|
| 0 | 02691156/points/d4d61a35e8b568fb7f1f82f6fc8747... | airplane | 4 |
| 1 | 03636649/points/eee7062babab62aa8930422448288e... | lamp | 4 |
| 2 | 04379243/points/90992c45f7b2ee7d71a48b5339c6e0... | table | 3 |
| 3 | 02691156/points/a3c928995562fca8ca8607f540cc62... | airplane | 4 |
| 4 | 03636649/points/85335cc8e6ac212a3834555ce6c51f... | lamp | 4 |
1 | |
1 | |
1 | |
1 | |
Augmentations
Point cloud에 적용될 수 있는 augmentation 코드입니다.
1 | |
Visualization
데이터를 시각화하여 확인합니다.
1 | |
1 | |
Data Loader
데이터 로더 코드입니다.
1 | |
DGCNN Model
DGCNN 모델 아키텍쳐를 구현한 코드입니다. 구현 코드는 [3]을 참고하여 작성되었습니다.
1 | |
1 | |
1 | |
1 | |
모델 성능 지표 - IoU
모델의 성능 확인을 위해 IoU(Intersection over Union)을 사용했습니다.
1 | |
Train
전체 학습 코드입니다.
1 | |
1 | |
1 | |
Test
학습에 사용되지 않은 데이터에 대해 예측해보는 test 코드입니다.
1 | |
1 | |
1 | |
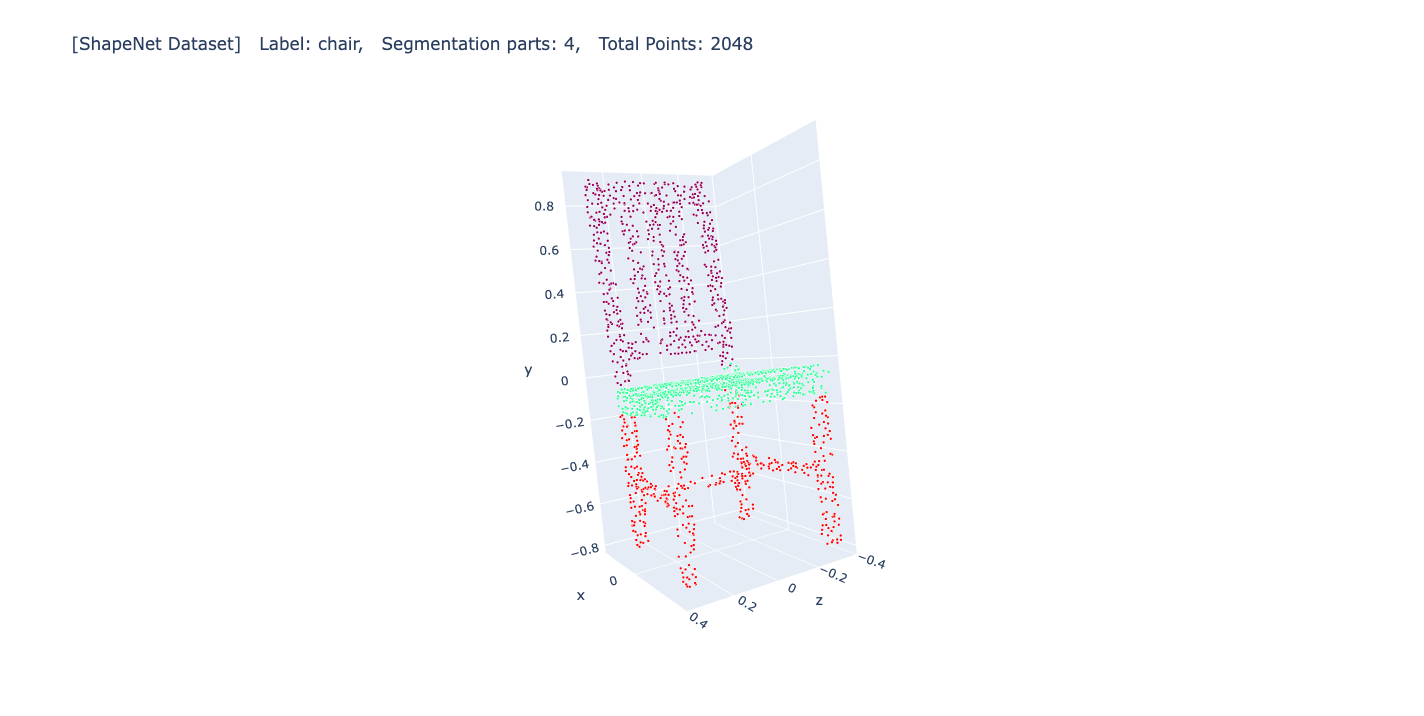
Prediction result
모델의 예측 결과입니다.
1 | |
1 |
|
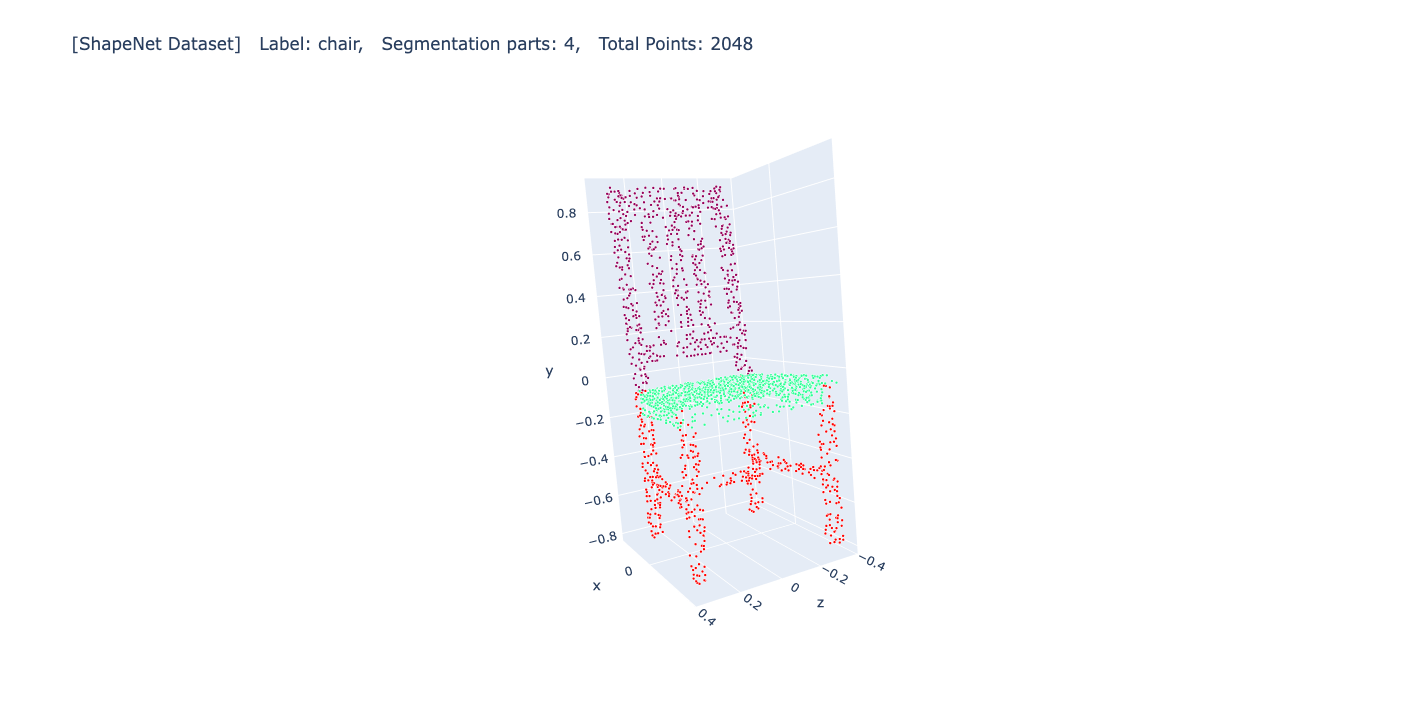
True label
실제 레이블입니다.
1 | |
1 |
|
참고 자료
[1] DGCNN paper: https://arxiv.org/abs/1801.07829v2
[2] PointNet paper: https://arxiv.org/abs/1612.00593
[3] Spatial Transformer Networks paper: https://arxiv.org/abs/1506.02025, NIPS 2015
[4] DGCNN 설명: https://www.youtube.com/watch?v=Rv3osRZWGbg
[5] PointNet 설명: https://jhyeup.tistory.com/entry/PointNet
[6] Spatial Transformer Networks 설명: https://www.youtube.com/watch?v=Rv3osRZWGbg
[7] Model code: https://github.com/AnTao97/dgcnn.pytorch/blob/master/model.py
[8] Dataset: https://github.com/AnTao97/PointCloudDatasets
[9] Data loading code : https://github.com/AnTao97/PointCloudDatasets/blob/master/dataset.py