대회 소개
VinBigData Chest X-ray Abnormalities Detection
Automatically localize and classify thoracic abnormalities from chest radiographs
Kaggle Link : https://www.kaggle.com/c/vinbigdata-chest-xray-abnormalities-detection/overview
패키지 불러오기
1 | |
kaggle에서 EfficientDet을 사용하기 위한 준비 과정
- VinBigData lib을 검색하여 현재 디렉토리에 추가해준다.(Add data)
- 아래 코드를 실행하여 wheel 설치를 진행하고, 경로를 추가해주면
effdet패키지를 사용할 수 있다.
1 | |
1 | |
1 | |
1 | |
데이터 경로 설정
1 | |
데이터 불러오기
- Bounding Box가 검출이 되지 않은 이미지는 제외해보자.
1 | |
| image_id | class_name | class_id | rad_id | x_min | y_min | x_max | y_max | width | height | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 9a5094b2563a1ef3ff50dc5c7ff71345 | Cardiomegaly | 3 | R10 | 691.0 | 1375.0 | 1653.0 | 1831.0 | 2080 | 2336 |
| 3 | 051132a778e61a86eb147c7c6f564dfe | Aortic enlargement | 0 | R10 | 1264.0 | 743.0 | 1611.0 | 1019.0 | 2304 | 2880 |
| 5 | 1c32170b4af4ce1a3030eb8167753b06 | Pleural thickening | 11 | R9 | 627.0 | 357.0 | 947.0 | 433.0 | 2540 | 3072 |
| 6 | 0c7a38f293d5f5e4846aa4ca6db4daf1 | ILD | 5 | R17 | 1347.0 | 245.0 | 2188.0 | 2169.0 | 2285 | 2555 |
| 7 | 47ed17dcb2cbeec15182ed335a8b5a9e | Nodule/Mass | 8 | R9 | 557.0 | 2352.0 | 675.0 | 2484.0 | 2568 | 3353 |
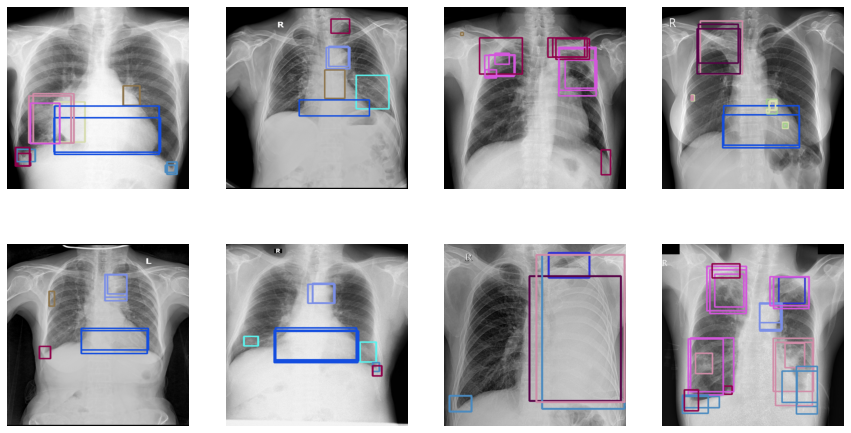
이미지 확인하기
한 이미지에서 여러 boundingbox가 겹쳐 보이는 이유는, multiple radiologists가 labeling을 했기 때문이다.
Data Description의 설명을 확인해보자.
Note that a key part of this competition is working with ground truth from multiple radiologists.
1 | |
데이터 전처리
데이터 로더 만들기
데이터 로더 만들 시 주의할 점은, 어떤 Detection 모델을 사용하느냐에 따라 boxes 좌표 순서가 바뀔 수 있다는 점이다.
EfficientDet 모델은 y_min, x_min, y_max, x_max 순서로 좌표가 들어가므로 이에 맞춰서 전처리를 해줘야 한다.
참고로 Kaggle에서 dicom 파일의 이미지들을 jpg 포맷으로 바꿔놓은 데이터가 올라와 있으므로, 이 데이터를 사용해보자.
1 | |
Train Valid 나누기
- Train, Valid 데이터는 8:2로 나눠보자.
- 데이터 로더에 들어갈 형식에 맞게 이미지 id들을 나눠준다.
1 | |
1 | |
transforms 함수 만들기
- 이미지들의 크기가 모두 다르기 때문에,
Resize함수로 전처리를 해준다. - 데이터 로더는 나중에 정의할 것이기 때문에, 여기서는
train_set,valid_set만 정의해주자.
1 | |
1 | |
모델 훈련을 위한 함수 정의
Fitter 클래스 정의
- 모델 학습 파이프라인을 설정해주자.
fit 함수
- 전체
Epoch동안의 학습 과정을 관리하는 함수이다.
train_one_epoch 함수
- 하나의
Epoch내의 모델 학습 과정을 관리하는 함수이다.
validation 함수
- 하나의
Epoch내의 valid 데이터 예측 및 평가 과정을 관리하는 함수이다.
save 함수
- 모델 학습 과정에서, 모델의 파라미터 저장 등을 관리하는 함수이다.
load 함수
- 저장된 모델 파라미터 등을 불러오는 함수이다.
logger 함수
- 학습이 진행되는 동안의 log를 기록하는 함수이다.
- AdamW, model.named_parameters 관련 참고 사이트
model.named_parameters() : https://comlini8-8.tistory.com/50
AdamW : https://hiddenbeginner.github.io/deeplearning/paperreview/2019/12/29/paper_review_AdamW.html
1 | |
AverageMeter 클래스 정의
- Loss 계산을 위한 클래스를 정의한다.
1 | |
TrainGlobalConfig 클래스 정의(하이퍼 파라미터 설정)
- Fitter 클래스에서 사용될 하이퍼파라미터를 설정한다.
1 | |
데이터로더 정의 및 학습 함수(Fit) 정의
DataLoader의 파라미터별 용도 참고 : https://subinium.github.io/pytorch-dataloader/shuffle: 데이터를 섞어서 불러오는 옵션sampler: shuffle과 유사한 옵션이나,index를 조정하는 옵션. 이 옵션을 사용하려면shuffle옵션은False(기본값)이어야 한다.RandomSampler: 랜덤으로 불러온다. Replacement 여부 선택 가능, 개수 선택 가능SequentialSampler: 항상 같은 순서로 불러온다.
pin_memory: 메모리 소모를 줄이는 옵션. Tensor를 CUDA 고정 메모리에 올린다.drop_last: Batch의 길이가 다른 경우에 따라 loss를 구하기 어려운 경우가 생기고, batch의 크기에 따른 의존도 높은 함수를 사용할 때 걱정이 되는 경우True옵션을 주어 마지막 batch를 사용하지 않을 수 있다.collate_fn: map-style 데이터셋에서 sample list를 batch 단위로 바꾸기 위해 필요한 옵션. Zero-padding이나 Variable Size 데이터 등 데이터 사이즈를 맞추기 위해 많이 사용한다.
1 | |
모델 정의
- 모델은
EfficientDet을 사용해본다. - pretrained를 True로 설정하고, 모델의 config.num_classes를 사용 목적에 맞게 꼭 바꿔주자. 그렇지 않으면 모델 학습시 input 사이즈 에러가 발생한다.
1 | |
모델 훈련
- 시드를 고정시킨 후, 학습을 진행한다.
1 | |
1 | |
결론
- EfficientDet b0를 사용한 베이스라인 코드이다.
- 여러 방사선 전문의들이 레이블링하였기 때문에 이러한
overlapping boxes에 대한 전처리가 필요할 것으로 보인다. -
또한, CutMix 기법, Weighted Boxes Fusion 등을 적용해볼 수 있다. 모델 역시 YOLOv5 등을 사용해볼 수 있다.
- 코드 참고 : https://www.kaggle.com/morizin/14-class-efficientdet-detection-train
Weighted Boxes Fusion Example
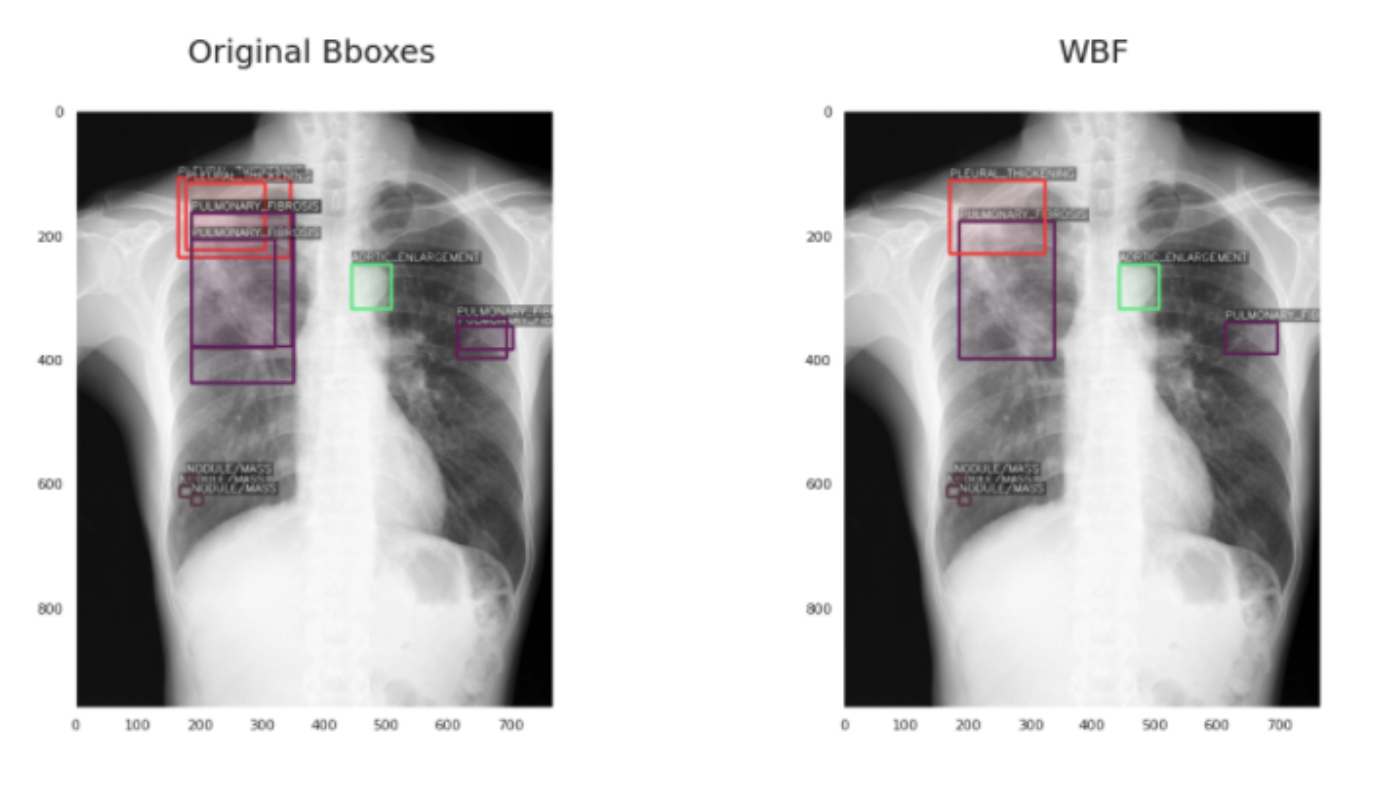
-
겹치는 박스(동일 레이블)를 처리할 수 있다.
-
Weighted Boxes Fusion 내용 : https://towardsdatascience.com/