Weighted Boxes Fusion 방법 소개

WBF(Weighted Boxes Fusion)
WBF는 Object detection 문제에서, 여러 바운딩 박스들을 앙상블하는 방법입니다. 모델은 이미지 내에 어디에(4개의 좌표값), 어떤 Class가(ex 사람/강아지/고양이), 얼마만큼의 확률(0~1)로 존재하는지 예측하게 됩니다. 만약 여러 모델에서 각기 다른 예측값들을 효과적으로 앙상블할 수 있다면, 모델의 성능을 더욱 높일 수 있을 것입니다.
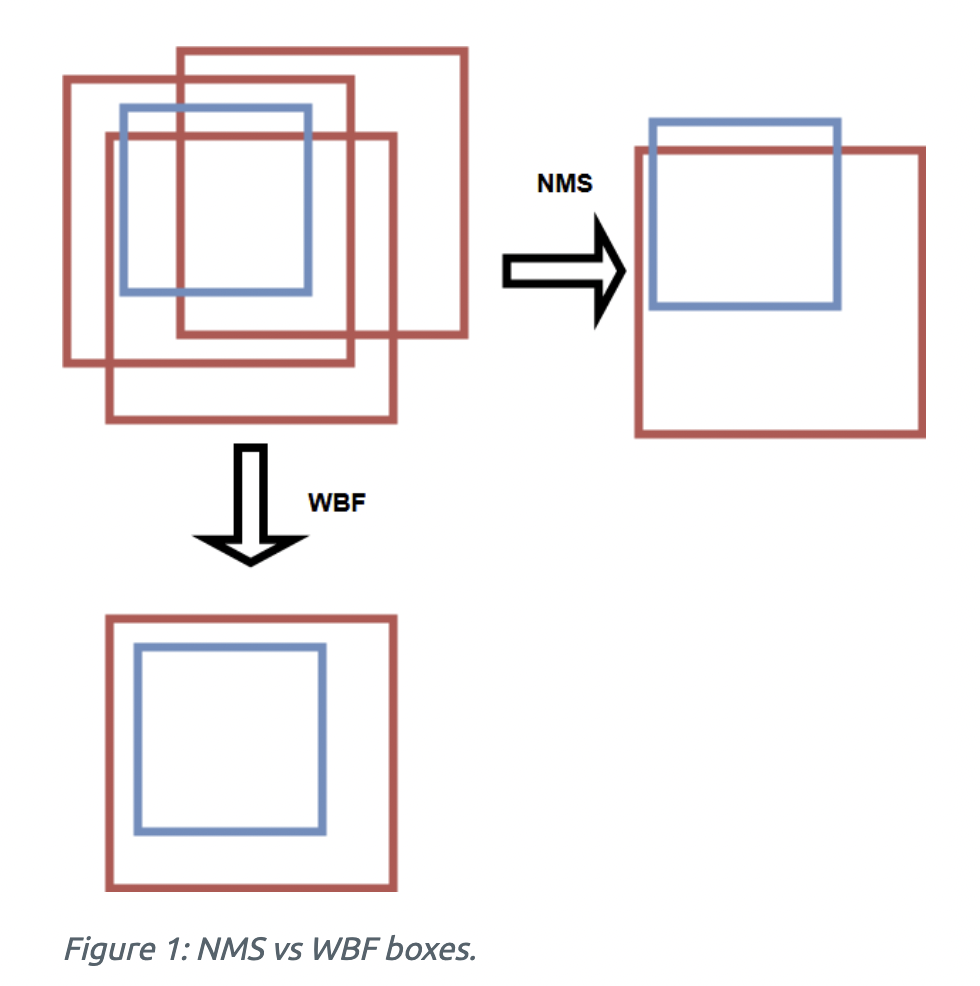
기존 NMS(Non Maximum Suppression)과 Soft-NMS extenstion의 방법도 존재합니다. NMS나 Soft-NMS는 예측값의 일부를 제거하는 방식이라면, WBF는 예측된 모든 바운딩 박스들의 정보를 사용하여 결합하는 방식입니다. 아래 이미지를 보면, 빨간색 박스가 모델의 예측값이고 파란색 박스가 정답값입니다. NMS는 부정확한 박스를 모두 제외하고 하나의 박스만 남겼다면, WBF는 예측된 3개의 박스의 정보를 모두 사용하여 최종 예측값을 뽑아냈습니다.
WBF의 알고리즘을 간단히 요약하자면, 두 박스의 IoU를 계산하여 iou_thr 임계값을 넘으면 융합이 진행되는데, 융합 시 예측된 각 박스의 score에 따라 결과가 조정되는 방식입니다. 예측 박스들을 융합하는 알고리즘은 아래 참고 블로그에서 더욱 자세하게 알 수 있습니다.
WBF 참고 블로그 : https://lv99.tistory.com/74
패키지 불러오기
1 | |
하이퍼파라미터 설정
1 | |
데이터 전처리
데이터셋 만들기(불러오기)
sample_submission파일을 불러옵니다.
1 | |
| image_id | PredictionString | |
|---|---|---|
| 0 | aac893a91 | 1.0 0 0 50 50 |
| 1 | 51f1be19e | 1.0 0 0 50 50 |
| 2 | f5a1f0358 | 1.0 0 0 50 50 |
| 3 | 796707dd7 | 1.0 0 0 50 50 |
| 4 | 51b3e36ab | 1.0 0 0 50 50 |
| 5 | 348a992bb | 1.0 0 0 50 50 |
| 6 | cc3532ff6 | 1.0 0 0 50 50 |
| 7 | 2fd875eaa | 1.0 0 0 50 50 |
| 8 | cb8d261a3 | 1.0 0 0 50 50 |
| 9 | 53f253011 | 1.0 0 0 50 50 |
데이터 로더 만들기
1 | |
1 | |
1 | |
모델 불러와서 Weighted Boxes Fusion 적용하기
모델 가중치 로드하기
- 5번의 교차검증으로 학습된 5개의 모델을 불러옵니다. 불러오기 전, 학습했을 때의 모델 구조로 바꿔줍니다.
- 추가하고자 하는 모델 가중치가 gpu 환경에서 학습되었기 때문에, 우리의 모델 역시 gpu 환경으로 맞춰줍니다. 만약 cpu로 예측을 하고 싶으면,
map_location옵션을cpu로 설정합니다. - 또한 데이터를 예측 시에는
model.eval()옵션을 줍니다. 이 옵션을 사용하면 모델 내부의 모든 layer가 evaluation 모드가 됩니다. Evaluation 모드에서는batchnorm,Dropout과 같은 기능들이 사용되지 않습니다.
1 | |
1 | |
5개 모델의 예측 결과 저장하는 함수 정의
make_ensemble_predictions함수는 5개의 모델의 예측값을 모두 저장하여 리스트 값으로 반환해주는 함수입니다.
1 | |
Weighted Boxes Fusion 함수 정의
- WBF 적용할 때는, bounding box 좌표값들이 0~1 사이의 값을 가져야 합니다. 아래 코드에서 좌표값들을
(image_size-1)로 나누는 이유가 바로 그것입니다. weighted_boxes_fusion함수에서,iou_thr과skip_box_thr하이퍼파라미터를 이해해야 합니다.iou_thr: IoU(Intersection over Union) 임계값입니다. 두 박스의 IoU를 계산하여, 임계값을 넘겼을 경우,config_type='avg'(디폴트 값) 방식으로 두 박스가 융합됩니다.skip_box_thrclass에 대한 예측 확률값(scores)이 skip_box_thr 임계값을 넘길 때만 가져옵니다.
1 | |
Weighted Boxes Fusion 적용 결과 확인
1. Weighted Boxes Fusion 적용하지 않았을 때
- 5개의 모델이 예측한 바운딩 박스를 모두 plot 해봤습니다. 모델 별로 색을 다르게 하여 구분할 수 있게 했습니다.
- 아래 결과 이미지를 보면, 5개 모델이 예측한 바운딩 박스들을 볼 수 있습니다.
1 | |

2. Weighted Boxes Fusion 적용했을 때
- WBF를 적용한 결과입니다.
1 | |

3. Weighted Boxes Fusion 적용 전과 후
- 왼쪽 이미지부터 원본, WBF 적용 전, WBF 적용 후의 이미지입니다.
1 | |
1 | |
중간 이미지는 5개의 모델에 대한 예측값들 모두 그려진 상태입니다. 모델이 각각 다른 가중치를 갖고 있기에 예측값도 조금씩 다릅니다. 이러한 예측값들을 모두 고려하여 WBF를 적용한 결과, 가장 오른쪽의 이미지와 같은 결과를 갖게 됩니다. 각 예측값의 score 값, 박스 간 IoU 값들을 기준으로 융합된 결과입니다.
제출하기
- 최근 kaggle에서는 예측값이 담긴 csv만 제출하는 것이 아니라, 부정행위를 방지하기 위해 notebook 전체를 제출하게끔 하고 있습니다.
- notebook으로 제출하기
-
- 오른쪽 콘솔에서
Internet을 끈다.
- 오른쪽 콘솔에서
-
Save Version->Advanced Settings->Always save output
-
- submission 파일 이름은 반드시
submission.csv로 설정하기
- submission 파일 이름은 반드시
-
- Save하여 제출
-
Submission 양식으로 바꿔주는 함수 정의하기
- 대회마다 submission 제출 양식이 다릅니다. 이 대회에서는 아래와 같은 제출 양식을 요구하고 있습니다. 즉
image_id별로 [class_score, xmin, ymin, width, height] 의 양식으로 들어가야 한다는 것입니다.
1 | |
| image_id | PredictionString | |
|---|---|---|
| 0 | aac893a91 | 1.0 0 0 50 50 |
| 1 | 51f1be19e | 1.0 0 0 50 50 |
| 2 | f5a1f0358 | 1.0 0 0 50 50 |
| 3 | 796707dd7 | 1.0 0 0 50 50 |
| 4 | 51b3e36ab | 1.0 0 0 50 50 |
1 | |
최종 예측
fasterrcnn_resnet50_fpn의 output은 자동적으로labels,scores,boxes값들이 dictionary 형태로 저장됩니다.- 또한 output의
boxes은[xmin, ymin, xmax, ymax]로 나오므로,[xmin, ymin, w, h]로 처리해줘야 합니다.
1 | |
| image_id | PredictionString | |
|---|---|---|
| 0 | aac893a91 | 0.9948 58 0 115 162 0.9921 618 914 74 109 0.98... |
| 1 | 51f1be19e | 0.9933 605 87 156 166 0.9898 278 470 133 121 0... |
| 2 | f5a1f0358 | 0.9972 886 645 86 141 0.9964 544 272 107 113 0... |
| 3 | 796707dd7 | 0.9935 710 823 107 101 0.9922 942 73 81 100 0.... |
| 4 | 51b3e36ab | 0.9986 836 450 186 145 0.9982 234 644 93 155 0... |
참고 자료
- Weighted Boxes Fusion Ensemble Code : https://www.kaggle.com/shonenkov/wbf-approach-for-ensemble
- Weighted Boxes Fusion Github : https://github.com/ZFTurbo/Weighted-Boxes-Fusion
- Weighted Boxes Fusion 정리 : https://lv99.tistory.com/74