대회 소개
APTOS 2019 Blindness Detection
Detect diabetic retinopathy to stop blindness before it’s too late
https://www.kaggle.com/c/aptos2019-blindness-detection
평가 지표 : Quadratic weighted kappa
요약
이번 프로젝트는 안저 이미지 데이터를 사용하여 당뇨성 망막증의 증상을 분류하는 모델을 구현하는 것입니다. 당뇨성 망막증은 당뇨병에 의해 망막의 미세혈관이 손상되어 발생하는 질병입니다. 세계 각국의 실명 원인 중에서 높은 비중을 차지하고 있기에 이를 초기에 발견하고 치료하는 것이 중요합니다. 하지만 충분한 의료 인력 및 인프라가 갖추어지지 않은 환경에서 이러한 질병을 발견하고 예방하기란 쉽지 않은 상황입니다. 이 대회에서는 당뇨성 망막증을 식별해내는 인공지능 모델을 개발하여 어떤 환경에서도 망막병증 환자들을 쉽고 빠르게 파악할 수 있기를 기대하고 있습니다.
데이터는 kaggle에서 진행된 APTOS 2019 Blindness Detection에서 제공하는 안저 이미지들입니다. 전체 이미지의 개수는 3662개이고, 각각 0~4 까지의 정수로 레이블링이 되어있습니다. 숫자가 높을수록 병증이 악화됨을 의미합니다. 대회의 평가 지표는 Quadratic weighted kappa입니다. 실제 레이블에서 모델의 예측값이 멀어질수록 더 큰 loss를 주는 방식이기 때문에, 이러한 레이블별 거리를 고려할 수 있도록 모델 학습시 crossentropy loss 대신 mean squared error를 사용했습니다.
모델은 Pre-trained된 ResNet18을 사용했으며, 모델 구조에 Squeeze and Excitation block을 추가했습니다. SE block는 feature map의 정보를 요약하고 그 중요도에 따라 채널 단위로 새로운 가중치를 주는 방식으로, 일종의 attention mechanism이라고 볼 수 있습니다. 이 방식을 제안한 [4]의 저자들은 SE block가 모델 구조 어떤 곳이라도 바로 붙일 수 있고, 계산 복잡도를 크게 증가시키지 않으면서도 모델의 성능을 많이 높일 수 있다는 장점이 있다고 말합니다.
아래는 앞서 이 프로젝트에서 적용했던 방식들을 비교한 표입니다. 모두 동일한 전처리(trim and resize(150,150)), 하이퍼 파라미터(learning rate=0.001, weight decay=0.005) 및 early stopping(patient=10) 조건을 사용했습니다. MSE loss를 사용했을 때 crossentropy loss보다 Test셋과 Valid셋 모두에서 더 높은 성능을 보여주었습니다(파란색). 또한 동일하게 MSE loss를 사용하는 상황에서는 SE block을 추가한 경우 Test 셋에 대해서는 private, public score 모두 향상되었고, 학습시에는 더 낮은 valid loss를 보여주었습니다(빨간색).
| Model | Loss | Private Score | Public Score | Valid QWK | Valid Loss |
|---|---|---|---|---|---|
| ResNet18 | CrossEntropy | 0.7183 | 0.4173 | 0.8142 | 0.6464 |
| ResNet18 | MSE | 0.7610 | 0.5091 | 0.8599 | 0.4247 |
| ResNet18 + SEBlock | MSE | 0.8310 | 0.6766 | 0.8491 | 0.4059 |
이번 프로젝트에서는 기본적인 전처리를 적용한 baseline 모델을 구현했습니다. 이후 정교한 하이퍼파라미터 튜닝이나 이미지 resize 및 여러 augmentation을 적용하여 모델의 성능을 끌어올릴 수 있습니다.
Packages
필요한 패키지들을 불러옵니다.
1 | |
Arguments
하이퍼파라미터 값들이 저장된 딕셔너리를 생성합니다.
1 | |
데이터 불러오기
1 | |
View Original Data
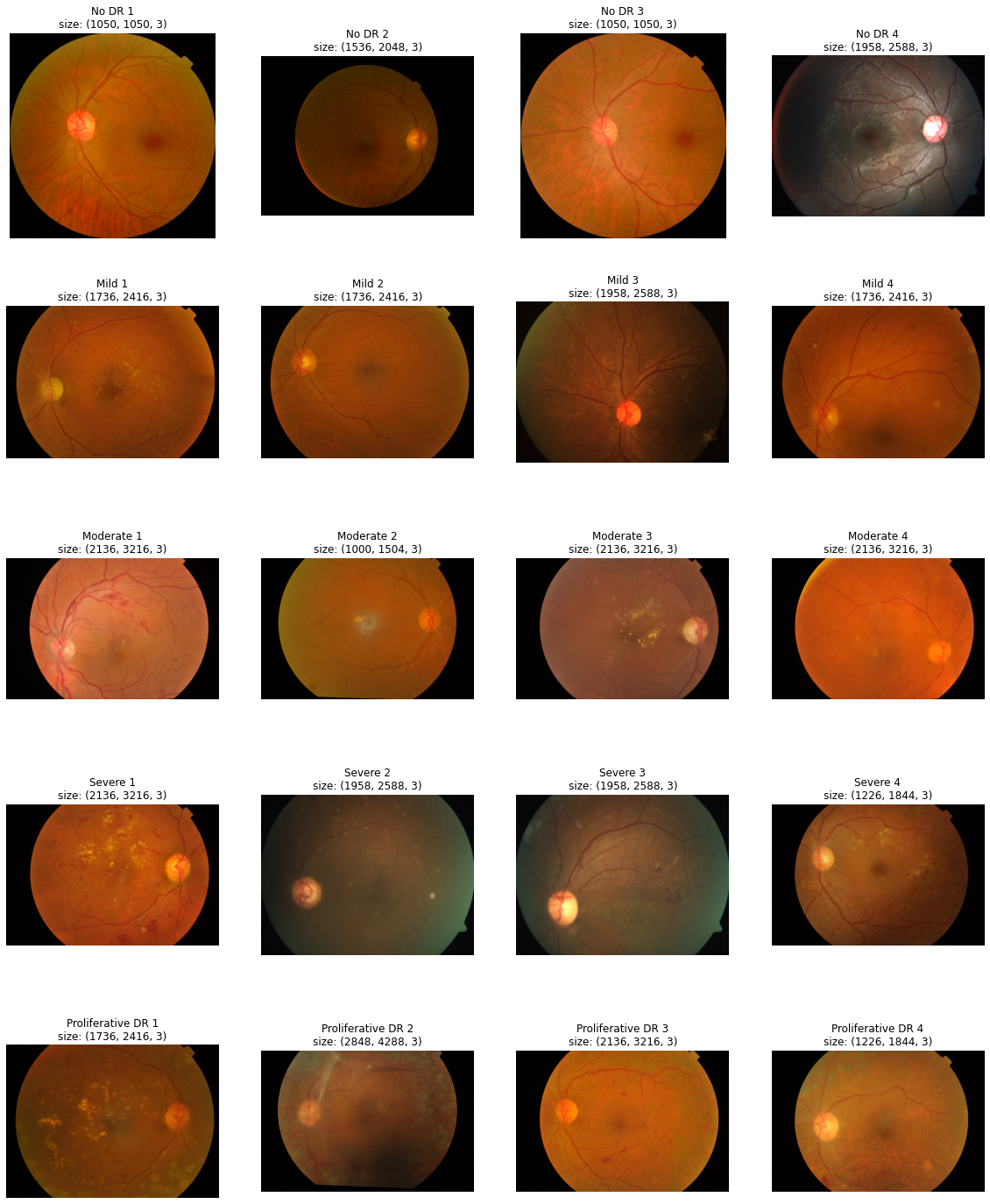
원본 데이터를 레이블 별로 확인해봅니다. Train data는 총 3662개, test data는 1928개가 있습니다. 아래는 각 레이블별 데이터의 개수입니다. 0에서 4로 갈수록 Diabetic retinopathy(DR, 당뇨성 망막증)의 병증이 악화됩니다. 전체 데이터 중 0(정상)의 비율이 50%로 다소 불균형한 데이터 분포를 보이고 있습니다. 또한, 아래 이미지를 보면 모든 데이터의 크기가 다른 것을 확인할 수 있습니다. 안저의 모양 역시 데이터별로 다릅니다.
0 - No DR / 1805개
1 - Mild / 370개
2 - Moderate / 999개
3 - Severe / 193개
4 - Proliferative DR / 295개
Total - 3662
1 | |
Preprocess(Trim & Resize)
Original data를 봤을 때, 안저 좌우로 검은 배경이 존재하는 것을 확인할 수 있습니다. 모델이 최대한 동일한 형태의 안저 이미지를 학습할 수 있도록, 좌우 검정 배경을 제거하고 안저의 비율을 유지한 상태로 크기를 Resize 해주었습니다. 아래 두 함수를 통해 이러한 전처리를 적용하였습니다.
1 | |
1. View trimmed & resized data
전처리한 이미지를 확인합니다.
1 | |
(1) Trimming Process
1 | |
1 | |

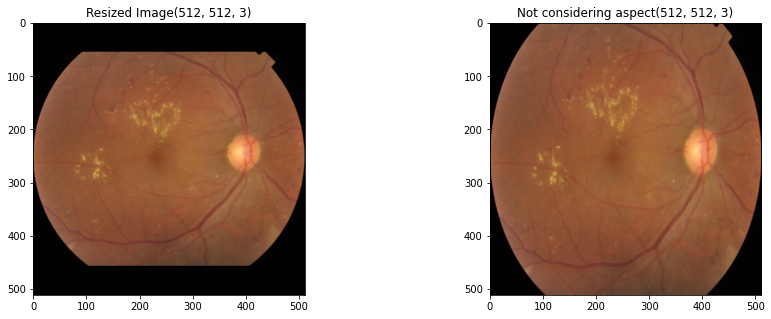
(2) Resize with its Aspect maintained
왼쪽 이미지는 안저 모양을 유지하면서 (512,512) 크기로 Resize해준 결과이고, 오른쪽 이미지는 검정 배경을 제거한 후, 바로 (512,512) 크기로 Resize한 결과입니다.
1 | |
1 | |
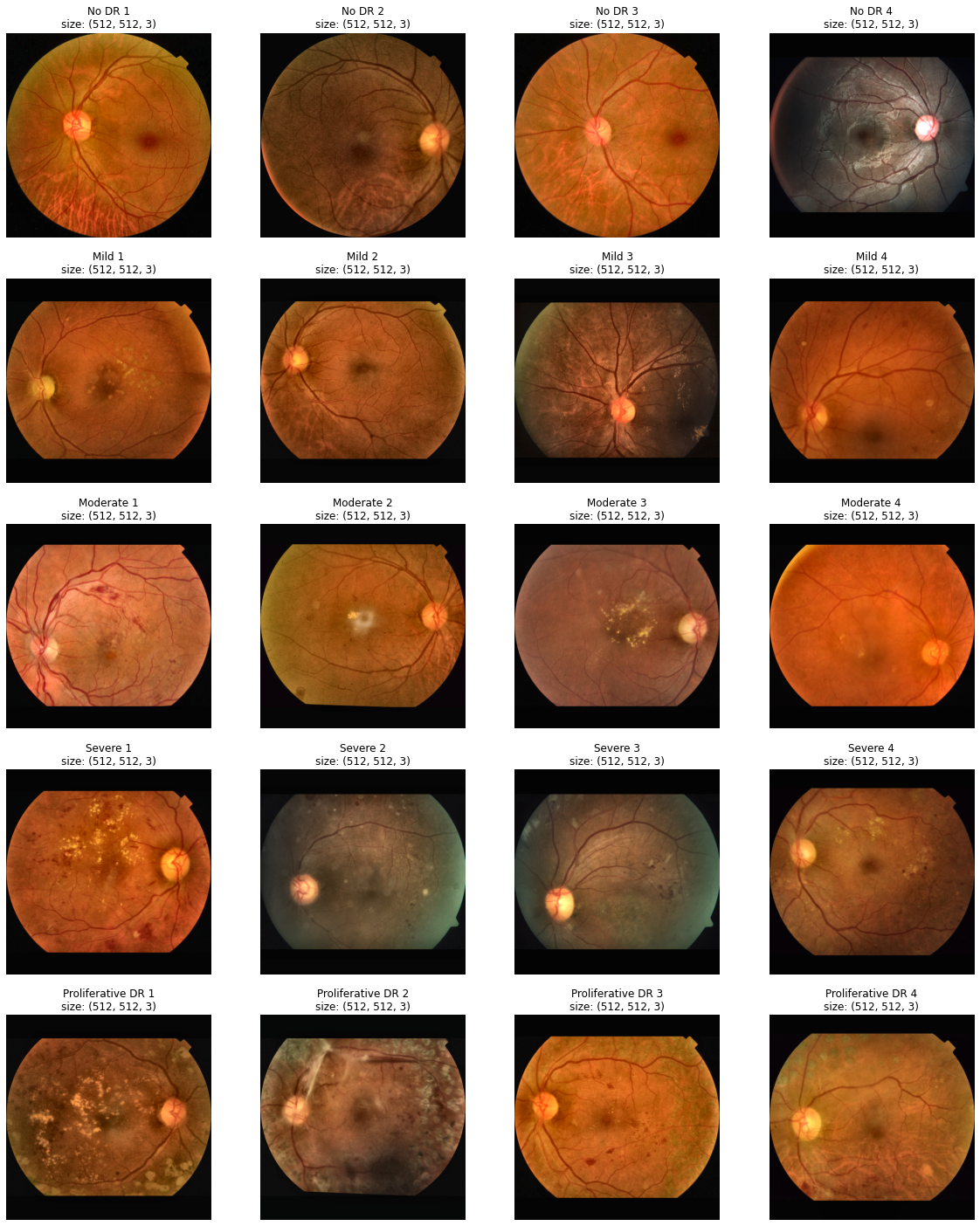
(3) Trim + Resize + CLAHE
전처리 결과입니다. 모든 안저 이미지의 좌우 검정 배경이 제거되었고, 기존 안저의 모양은 유지하면서 크기가 (512,512)로 모두 맞춰진 것을 확인할 수 있습니다.
1 | |
Transforms
Train 데이터셋에 적용되는 augmentation입니다. HorizontalFlip, VerticalFlip, RandomRotate90, CLAHE와 Normalize를 적용해주었습니다.
1 | |
Data Loader
데이터 로더 클래스를 정의합니다. 사전에 이미지를 np 형태로 저장해놓았고, 이를 불러오게끔 코드로 처리하였습니다.
1 | |
데이터셋 나누기
train과 valid 데이터는 8:2의 비율로 각 레이블별 비율을 유지하면서 나누어 주었습니다.
1 | |
데이터셋 나누기
데이터 로더를 적용하여 Train, Valid, Test셋을 배치 형태로 만들어 줍니다.
1 | |
Check Augmentations in Data Loader
최종적으로 데이터로더를 통해 학습되는 데이터를 확인합니다.
1 | |
1 | |
Utils
대회의 평가 지표는 Quadratic weighted kappa(QWK)입니다. 간단히 설명하자면 이 평가지표에서는 실제 레이블에서 모델의 예측값이 멀어질수록 더 큰 loss를 줍니다. 모델이 레이블에 최대한 가까운 예측값을 추출할 수 있도록 학습시켜야하기 때문에, MSE Loss를 사용했습니다. 아래 표는 Trim 전처리와 (150,150) Resize만 하여 모델을 학습시켜본 결과입니다. Crossentropy loss를 사용했을때보다 MSE Loss를 사용했을 때 valid 데이터와 test 데이터에서 더 좋은 결과를 보여주었습니다.
| Model | Loss | Private Score | Public Score | Valid QWK | Valid Loss |
|---|---|---|---|---|---|
| ResNet18 | MSE | 0.7610 | 0.5091 | 0.8599 | 0.4247 |
| ResNet18 | CrossEntropy | 0.7183 | 0.4173 | 0.8142 | 0.6464 |
1 | |
1 | |
1 | |
Train
학습 함수입니다.
1 | |
SE Block
ResNet18에 Squeeze and Excitation Block(SE Block)을 추가했습니다. SE Block을 통해 Convolution 연산을 거친 피쳐맵에서 중요한 정보들을 압축(Squeeze)하고 재조정(Recalibration)할 수 있습니다. 중요 정보를 추출하는 과정에서는 GAP(Global Average Pooling)을 사용하고, 재조정 과정에서는 Fully Connected Layer과 비선형 함수인 ReLU, Sigmoid이 사용됩니다. 결국 SE Block을 거치게 되면 피쳐맵이 채널들의 중요도에 따라 스케일 됩니다.
실제 아래 실험 결과표에서 확인할 수 있듯이, ResNet18 모델 구조에 SEBlock을 추가했을 경우 test셋에 대한 Quadratic Weighted Kappa 점수가 더 높은 것을 확인할 수 있습니다.
| Model | Loss | Private Score | Public Score | Valid QWK | Valid Loss |
|---|---|---|---|---|---|
| ResNet18 | MSE | 0.7610 | 0.5091 | 0.8599 | 0.4247 |
| ResNet18 + SEBlock | MSE | 0.8310 | 0.6766 | 0.8491 | 0.4059 |
Squeeze and Excitation에 대한 더 자세한 설명은 아래 블로그를 참고하시면 됩니다.
-
SE 설명 참고 : https://jayhey.github.io/deep%20learning/2018/07/18/SENet/
-
코드 참고 : https://github.com/edshkim98/ChannelwiseAttention/blob/main/resnet_se.py
1 | |
SE Block을 ResNet18 모델 구조에 추가하기
1 | |
전체 학습 함수
학습 함수 코드입니다. Automatic Mixed Precision을 적용했습니다. AMP를 사용하였을 때의 장점은 아래와 같습니다.
- 처리 속도를 높이기 위한 FP16(16bit floating point)연산과 정확도 유지를 위한 FP32 연산을 섞어 학습하는 방법.
- Tensor Core를 활용한 FP16연산을 이용하면 FP32연산 대비 절반의 메모리 사용량과 8배의 연산 처리량 & 2배의 메모리 처리량 효과가 있음.
1 | |
학습시키기
랜덤 시드를 고정시키고 학습 시킵니다.
1 | |
1 | |
Test
Test셋에 대한 예측과 예측 결과값을 submission.csv에 저장합니다.
1 | |
1 | |
1 | |
| id_code | diagnosis | |
|---|---|---|
| 0 | 0005cfc8afb6 | 2 |
| 1 | 003f0afdcd15 | 2 |
| 2 | 006efc72b638 | 2 |
| 3 | 00836aaacf06 | 2 |
| 4 | 009245722fa4 | 3 |
| ... | ... | ... |
| 1923 | ff2fd94448de | 3 |
| 1924 | ff4c945d9b17 | 2 |
| 1925 | ff64897ac0d8 | 2 |
| 1926 | ffa73465b705 | 2 |
| 1927 | ffdc2152d455 | 1 |
1928 rows × 2 columns
결론
이번 프로젝트에서는 pre-trained ResNet18에 SEBlock을 적용한 베이스라인 모델을 만들었습니다. 이후 하이퍼파라미터 튜닝 및 다른 모델 구조들을 적용하여 점수를 높일 수 있습니다. 현재 학습에는 동일한 random seed로 train과 valid를 8:2로 나눈 데이터셋을 사용했는데, 5-fold cross validation과 soft-voting과 같은 방식으로 여러 모델을 앙상블하여 더욱 강건한 예측값을 뽑아낼 수도 있을 것으로 기대합니다. 또한 https://www.kaggle.com/c/diabetic-retinopathy-detection/data 대회에서 제공하고 있는 약 35,000개의 Fundus 이미지를 학습한 모델에 transfer learning을 시켜주어 정확도를 더 높일 수도 있을 것입니다.
참고 자료
[1] Squeeze and Excitation Block (1): https://github.com/edshkim98/ChannelwiseAttention/blob/main/resnet_se.py
[2] Squeeze and Excitation Block (2): https://jayhey.github.io/deep%20learning/2018/07/18/SENet/
[3] Quadratic Weighted Kappa: https://www.kaggle.com/aroraaman/quadratic-kappa-metric-explained-in-5-simple-steps
[4] https://arxiv.org/abs/1709.01507